

Web scraping is an important technique for extracting information from websites, allowing users to gather data efficiently and systematically. By automating the process of collecting data, web scraping can save time and provide access to large amounts of information that would be impossible to gather manually.
In this article, we will put our knowledge into practice with the basics of web scraping with Beautiful Soup, a powerful Python library designed for parsing HTML and XML documents. For a comprehensive understanding of web scraping, you can read our previous articles on web scraping and web scraping tools. They provide a solid foundation for anyone new to the field and looking to hit the ground running.

What is Beautiful Soup?
Beautiful Soup is a versatile library in Python that can be used for web scraping. It pulls data out of HTML and XML files and creates a parse tree from page source codes that can be used to extract data easily. This lends itself well to applications in research, business intelligence, and competitive analysis, among others.
HTML and XML are standard languages used to create and structure data on the web. HTML is mainly used to create web pages and web applications. It defines elements like headings, paragraphs, and links. XML, on the other hand, is designed to store and transport data in a way that is both readable by humans and machines.
A parse tree, in the context of web scraping, is a hierarchical structure that represents the syntax of a document. It breaks the document down into its constituent parts, such as tags, attributes, and text, in a tree-like format. This structure allows for easy navigation of the document, making data extraction more efficient.
When you make an HTTP request to a webpage, the server responds with the page’s HTML content — which you can see by looking at the page source of any web page. Beautiful Soup takes this raw HTML and transforms it into a parse tree, which lets you find specific elements as needed.
Compared to other web scraping libraries, Beautiful Soup has its advantages. Unlike Selenium, which is designed for interacting with dynamic and JavaScript-heavy web pages, Beautiful Soup excels at parsing and extracting data from static HTML content. It is also simpler and more lightweight than comprehensive frameworks like Scrapy.

Understanding HTML Structure
HTML documents are structured with tags, which we’ve learned to identify elements like headings, paragraphs, links, and images. Each tag is enclosed in angle brackets (e.g. <tag>), and many elements have opening and closing tags (e.g. <p></p> for paragraphs). Tags can also have attributes that provide additional information about the element, such as id, class, and src for images.
Understanding HTML is important for web scraping because it lets you navigate to and extract the specific data you need from the page. This, in turn, will enable you to write more precise scripts.
Here is a simple example of HTML.
<!DOCTYPE html>
<html>
<head>
<title>Sample HTML Document</title>
</head>
<body>
<h1>Welcome to My Web Page</h1>
<p>This is a paragraph of text on my web page.</p>
<a href="https://example.com">Visit Example.com</a>
<img src="image.jpg" alt="Sample Image">
</body>
</html>And here you can see how the HTML translates to a web page.
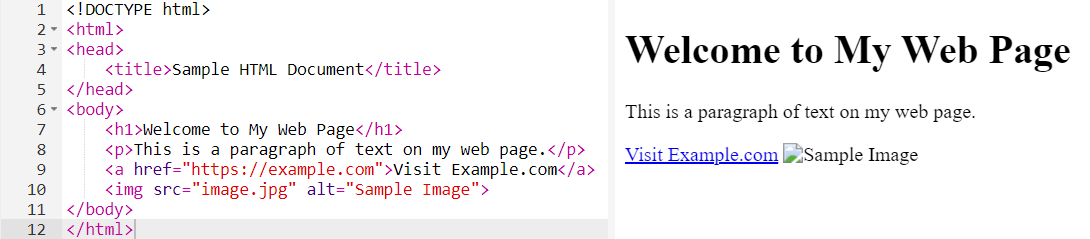
Now that we have a basic understanding of HTML structure, let’s apply it in a hypothetical situation.

Step-By-Step Guide to Web Scraping With Beautiful Soup
Web scraping with Beautiful Soup and mobile proxies is a powerful combination for extracting data from websites while maintaining anonymity and avoiding IP bans. Here’s a step-by-step guide on how to use Beautiful Soup with mobile proxies:
Step 1: Install Python
Make sure you have Python installed on your system. If not, download and install it from the official Python website.
Step 2: Install Required Libraries
Make sure you have Python installed on your system. You will need to install the following libraries, if you haven’t already, using pip (Python’s package manager):
pip install requests
pip install beautifulsoup4
pip install pandasStep 3: Import Libraries
In your Python script, import the necessary libraries:
import requests
from bs4 import BeautifulSoup
import pandas as pd
#Added pandas library for Excel exportStep 4: Make an HTTP Request
Use the requests library to make an HTTP request to your target URL. In this case we’ll be using the hypothetical link https://example.com/product-page.
We’ll go one step further and include a way to check whether the request was successful, too.
In the event the request is successful, we’ll create an object called soup from the HTML document. If it is unsuccessful, our code will give us an error message.
url = "https://example.com/product-page"
response = requests.get(url)
response.raise_for_status()
# Check if the request was successful
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# You can now use Beautiful Soup to parse the HTML content.
else:
print(f"Request failed with status code: {response.status_code}")Step 5: Scrape Product Name and Price with Beautiful Soup
Now we can use Beautiful Soup to parse and extract the names and prices of all the products on the page.
We’ll start by creating lists to store the names and prices of each product.
For the sake of this example, we’ll assume that each product on the page is identified by the class product, its name is noted as product-name and its price as product-price.
In reality, these will be different on the website you want to scrape from. You’ll have to amend your script to reflect this.
# Lists to store product names and prices
product_names = []
product_prices = []
# Find all the div elements with class 'product'
products = soup.find_all('div', class_='product')
# Iterate over each product found
for product in products:
# Find the product name
name = product.find(class_='product-name').text
product_names.append(name)
# Find the product price
price = product.find(class_= 'product-price').text
product_prices.append(price)For every product on the page, the script will find the name and price and add it to the lists.
The .text attribute in the code will remove the HTML tags and return only the text inside the element.
Step 6: Store Scraped Data in an Excel Sheet
Next, we’ll store the product’s name and price in a DataFrame and save it to an Excel sheet.
Then we’ll have our script tell us whether the data was successfully saved or not.
# Store the product name and price data in a DataFrame
data = { "Product Name": product_names, "Price": product_prices }
df = pd.DataFrame(data)
# Define the Excel file name
excel_file = "product_pricing.xlsx"
# Save the DataFrame to an Excel file
df.to_excel(excel_file, index=False)
# Print a message to confirm that the data is saved
print(f"Product pricing saved to {excel_file}")
else: print(f"Request failed with status code: {response.status_code}")
Common Web Scraping Challenges
Web scraping is rarely straightforward. There are many challenges that will hamper your activities, and you’ll have to account for each of them.
One common challenge is missing or inconsistent data. Websites may have varying structures and not all the elements you’re looking for will be present on every page. This means your script will have to account for and handle these inconsistencies.
Dynamic content is another obstacle, as some websites load data using JavaScript after the initial HTML page has been delivered. In these cases, libraries like Selenium would be more appropriate, as they can render JavaScript and access the dynamically loaded content.
Anti-scraping mechanisms like CAPTCHAs are designed to prevent automated access to websites. While a nuisance, using captcha solvers can help bypass them. Websites may also implement rate limiting and IP blocking to combat bots. Using a pool of proxies can distribute your requests over several IPs and reduce the likelihood of being blocked.
Lastly, websites frequently change their structure, which can break your scripts. This means you’ll need to routinely update your scripts to handle any changes in the website’s layout or structure.
Conclusion
In this article, we covered the basics of web scraping with Beautiful Soup. We learned how to set up our environment by installing the necessary libraries and how to use Beautiful Soup to navigate and extract data from HTML content.
We also explored the structure of HTML documents, understanding how tags, attributes, and text elements are used to build web pages.
With our step-by-step guide, we learned how to make HTTP requests, parse HTML content with Beautiful Soup, and extract product names and prices from a sample e-commerce page. We then demonstrated how to store the extracted data in a DataFrame and save it to an Excel file, making it easy to manage and analyze the collected information.
With this basic guide, you should be more comfortable dipping your toes into starting own web scraping project and effectively gather data from websites.





