

Data normalization is an integral part of database design as it organizes information structures to eliminate redundancy and maintain data integrity. This methodical process transforms chaotic data collection into logical arrangement through normal forms which are progressive rules that prevent anomalies through insertion, update, and deletion operations.
For database professionals who face increasingly complex data environments, mastering data normalization principles provides the foundation for systems that remain reliable at scale while optimizing both storage and performance. This article will navigate the technical progression from basic normalization concepts through advanced forms, offering practical implementation strategies that balance theoretical rigor with real-world application requirements.

Defining Data Normalization
Data normalization organizes database information to cut down redundancy and improve data integrity. The process of normalization structures your database by creating tables and linking them according to specific rules. These rules, called normal forms, eliminate duplicate data and make your database run smoothly.
Picture organizing your closet as a way to understand data normalization. Rather than throwing all your clothes into one big pile (unnormalized data), you sort them by type, color, or season (normalized data). This setup lets you find items quickly without keeping extras. A relational database needs smaller, focused tables instead of large ones. These tables connect through primary and foreign keys. The result is a logical arrangement that makes maintenance and queries easier.
Purpose of Normalization in Databases and Analytics
The primary purpose of data normalization in database design is to minimize redundancy while preserving data integrity. When you normalize your database, you:
- Reduce storage requirements by eliminating duplicate data.
- Maintain consistency across your dataset.
- Simplify data maintenance and updates.
- Protect against data anomalies that can corrupt information.
Beyond database management, normalization serves critical purposes in analytics and machine learning. In these contexts, normalization often refers to feature scaling which means adjusting values measured on different scales to a common scale. This statistical normalization ensures that no single feature dominates the analysis simply because of its larger magnitude. Proper data normalization facilitates more accurate data analysis by preventing the “garbage in, garbage out” problem. When your data structure is clean and logical, your analytical results become more reliable and interpretable.
Common Problems Caused by Unnormalized Data
Unnormalized data creates several problems that can impact your database performance and data quality. Insertion anomalies occur when you cannot add new data without first adding other, potentially unrelated data. For example, in an unnormalized school database, you might be unable to add new courses until at least one student enrolls. Update anomalies happen when changing a single data item requires multiple updates across numerous records. This increases the risk of inconsistency if some updates succeed while others fail. Deletion anomalies happen when removing one piece of information inadvertently deletes other, unrelated data. For instance, deleting the last student enrolled in a course might also delete all information about that course.
Additionally, unnormalized data frequently suffers from excessive storage requirements due to repeated data, slower query performance with complex joins, difficulty maintaining data consistency across the database, and challenges in implementing database security at a granular level. These issues compound as your database grows, making normalization an essential practice for sustainable database design. By applying normalization techniques through the various normal forms (1NF, 2NF, 3NF, and BCNF), you can create a solid foundation for reliable data management and analysis.

Understanding Data Normalization Forms
Normal forms represent the cornerstone of database normalization. They provide rules that help structure relational databases properly. Each form builds on the previous one and eliminates different types of data redundancies and anomalies.
First Normal Form (1NF): Atomic Values and Unique Rows
First Normal Form establishes the fundamental requirements for a relational database. A table is in 1NF when it meets the following criteria:
- Each column contains only atomic (indivisible) values.
- No repeating groups exist in the table.
- Each row is unique, typically ensured by defining a primary key.
Atomicity means the database management system cannot break down values into smaller, meaningful parts. As an example, a “FullName” field with “John Smith” is atomic if the system treats it as one value despite containing both the first and last name. Modern relational database systems enforce 1NF automatically since they do not allow nested tables. Data migration from non-relational (NoSQL) databases to relational systems needs normalization to 1NF as the first crucial step.
Second Normal Form (2NF): Full Functional Dependency
Second Normal Form (2NF) fixes split dependencies in your database. After getting your data into First Normal Form, you need to make sure each piece of information depends on the entire primary key, not just part of it. This mainly matters when your primary key combines multiple columns. By organizing your data properly in 2NF, you avoid storing the same information multiple times and prevent update problems.
As an example, a course enrollment table with {StudentID, CourseID} as its composite key might have CourseLocation depending only on CourseID instead of the whole key. This is a partial dependency. You will need to split the tables into multiples to achieve 2NF. Each non-key attribute should fully depend on its table’s primary key. This split reduces redundant data and prevents update problems where changing one piece of data needs multiple updates.
To fix a partial dependency, split your data into separate tables. In the example, move CourseLocation into a new Courses table where CourseID is the primary key. This way, CourseLocation fully depends on its table’s entire primary key instead of just part of a composite key. The original enrollment table would keep only data that depends on both StudentID and CourseID. This eliminates redundancy since course information is stored just once per course rather than repeatedly for each student enrollment.
Third Normal Form (3NF): Removing Transitive Dependencies
Third Normal Form fixes chain-reaction dependencies in your data. After setting up 2NF, you need to make sure each piece of information depends only on the primary key, not on other regular columns. For example, if you store student information with their department and department head, the department head doesn’t depend on the student, it depends on the department. These indirect connections create problems when you update your data. The solution is simple: split your data into more tables where each piece of information connects directly to the right primary key. This way, you store each fact only once, in exactly one place, making your database more reliable.
Boyce-Codd Normal Form (BCNF): Candidate Key Constraints
BCNF, sometimes referred to as 3.5NF, works as a stricter version of 3NF. BCNF ensures that for every relationship in your database where one field determines another field’s value, the determining field must be able to uniquely identify each record. This rule helps eliminate redundant data and makes your database more efficient by storing each piece of information exactly where it belongs.. BCNF is different from 3NF as it does not make exceptions for dependencies with prime attributes. This strict rule eliminates all redundancy based on functional dependencies, even if other types still exist. Tables with multiple overlapping candidate keys need BCNF. Despite that, BCNF decomposition might not preserve all dependencies so you might need to balance complete normalization against practical needs.

Steps to Normalizing Data
Data normalization needs a clear approach that works for beginners. The following workflow breaks down this process into manageable steps that you can apply to any dataset.
Step 1: Identify Repeating or Redundant Data
Your data normalization experience starts with looking at your current data structure. Look for columns that have the same information across multiple rows. These repeating patterns show you where you need to normalize. As an example, customer contact details that show up multiple times in order records would tell you that separate tables might work better. In this instance, you should look for fields that show up often with similar values, related attributes that repeat together, and text fields that pack multiple pieces of information. Mark these repeated items as candidates for new tables. This step will create the foundation for all your data normalization work ahead.
Step 2: Break Data into Logical Tables
Next up, you should split your data into separate tables based on the patterns you found. Each table needs to represent just one entity or concept. You have to think about the data’s structure as well as how people will use it. Some rules for creating good tables include:
- Keep related attributes together.
- Give each table one clear purpose.
- Do not mix different types of entities in one table.
Step 3: Apply Primary and Foreign Keys
For the next step, consider creating links between your new tables with primary and foreign keys. A primary key will give each row its unique identity. Foreign keys will point to the primary keys in other tables and build relationships between them. Your database design will work best when you pick primary keys that stay consistent, build composite keys when needed, and set up foreign key rules that keep data consistent.
Step 4: Validate Against Normal Forms
Finally, you can assess each table against the normal forms we had previously discussed. Start with First Normal Form (1NF) and work your way up. Doing this will give you a database structure that follows normalization rules. Make sure to check the following points:
- Each table meets 1NF with atomic values and a primary key
- No partial dependencies break 2NF
- No transitive dependencies violate 3NF
- BCNF criteria fit your specific case
Data Normalization Rules and Examples
Data normalization needs rule understanding and hands-on practice to perfect. You will become skilled at designing databases that strike the perfect balance between speed and data accuracy once you grasp these simple concepts.
Each normal form has specific rules that build on the previous one. First Normal Form (1NF) requires that all columns have atomic values, each row has a unique identification, each column has a unique name, and that the data order does not matter.
Second Normal Form (2NF) builds on 1NF and needs everything from 1NF as well as no partial dependencies, meaning all non-key attributes must depend on the whole primary key and not just parts of it. Third Normal Form (3NF) takes 2NF further and needs everything from 2NF on top of no transitive dependencies, meaning non-prime attributes cannot depend on other non-prime attributes. Finally, Boyce-Codd Normal Form (BCNF) adds to 3NF as X must be a superkey for every non-trivial functional dependency X – Y.
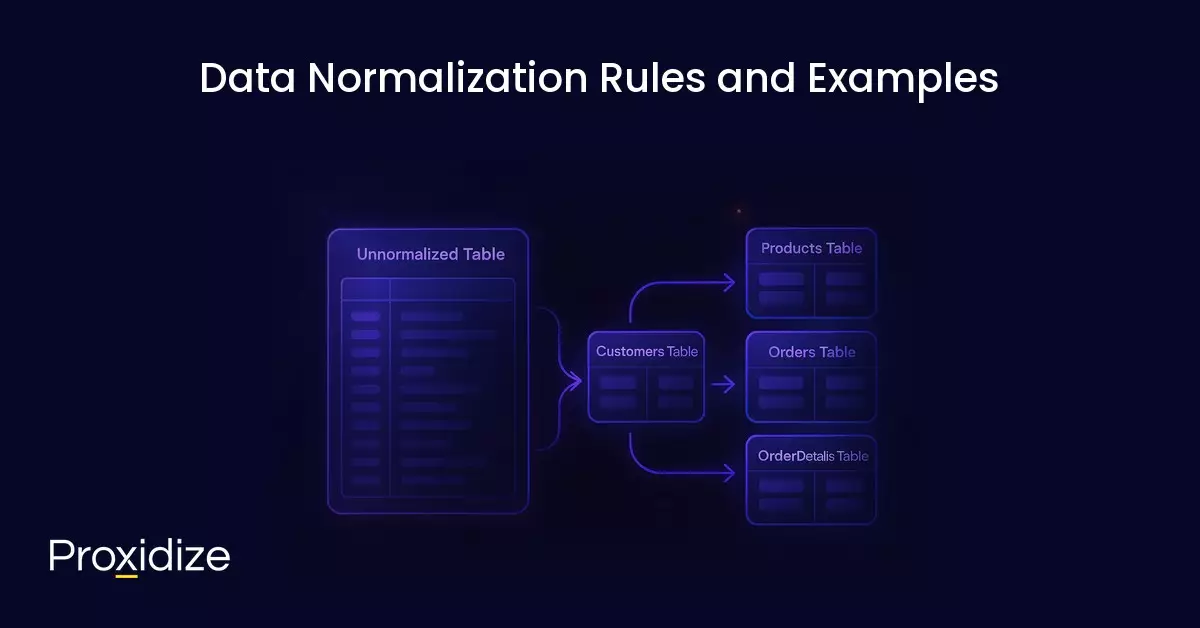
Let’s look at this unnormalized table with customer order details:
| OrderID | Customer_Name | Customer_Address | Product_ID | Product_Name | Price | Quantity |
|---|---|---|---|---|---|---|
| 1001 | John Smith | 123 Main St | P100 | Keyboard | 49.99 | 1 |
| 1001 | John Smith | 123 Main St | P200 | Mouse | 19.99 | 2 |
| 1002 | Alice Jones | 456 Oak Ave | P100 | Keyboard | 49.99 | 1 |
This table breaks several data normalization rules. Here’s how we split it into 3NF tables:
Customers Table (3NF):
| CustomerID | Customer_Name | Customer_Address |
|---|---|---|
| C1 | John Smith | 123 Main St |
| C2 | Alice Jones | 456 Oak Ave |
Products Table (3NF):
| ProductID | Product_Name | Price |
|---|---|---|
| P100 | Keyboard | 49.99 |
| P200 | Mouse | 19.99 |
Orders Table (3NF):
| OrderID | CustomerID | Order_Date |
|---|---|---|
| 1001 | C1 | 2025-06-27 |
| 1002 | C2 | 2025-06-28 |
OrderDetails Table (3NF):
| OrderID | ProductID | Quantity |
|---|---|---|
| 1001 | P100 | 1 |
| 1001 | P200 | 2 |
| 1002 | P100 | 1 |
Real-World Data Normalization Applications
Data normalization in the real world follows these steps:
- Identify Entities: Find distinct data groups like customers, products, and orders.
- Apply 1NF: Make all values atomic and create primary keys to remove repeating groups.
- Apply 2NF: Create separate tables where attributes fully depend on the key to remove partial dependencies.
- Apply 3NF: Make more tables as needed to remove transitive dependencies.
- Consider BCNF: More complex databases with multiple candidate keys might need you to use BCNF.
Data normalization can help prevent data issues while making databases more efficient. Real-world projects might need different levels of normalization. You might occasionally need to denormalize parts of the database to make it faster, especially in data warehouses where quick queries matter more than updates.

Benefits and Challenges of Data Normalization
Data normalization offers many benefits to database systems, but usually comes with some challenges that designers need to handle with care.
Improved Data Integrity and Consistency
Normalization improves data integrity by removing redundancies, as all your data exists in just one place. This single-source approach means you only update information once, which prevents the inconsistencies found in unnormalized designs. A properly normalized relational database reduces the risk of data corruption. Your database becomes more reliable and trustworthy through careful structuring based on normal forms.
Normalized databases enforce data consistency through constraints and relationships. Foreign key constraints maintain referential integrity to keep related data in sync. This organization makes it easier to apply business rules and validation logic, which leads to better data quality.
Faster Query Performance and Reduced Storage
Data normalization makes most database operations faster, as a normalized database would need less storage. This reduces I/O operations and makes disk usage more efficient. Normalized databases can save up to 80% in storage costs when compared to unnormalized ones.
Normalized tables allow for faster access and better indexing strategies for simple queries and transactions. This happens because database engines can cache and process smaller, focused tables more efficiently.
Slower Joins and Complex Design
Highly normalized databases can struggle with complex analytical queries that need multiple joins. More tables through data normalization can slow down queries that need data from many sources.
Complex join operations use more CPU and memory, especially in big systems. The design complexity presents another challenge as building a properly normalized database needs knowledge of functional dependencies and normalization principles. These tend to be skills that not all developers have.
Benefits of Denormalization
There are some cases where denormalization might be a better option. For an OLAP (Online Analytical Processing) system where read operations outnumber writers, selective denormalization often improves performance. Data warehouses commonly have denormalized structures to facilitate complex reporting and analysis. Denormalization benefits real-time systems that require minimal response latency.
By reducing joins and precomputing frequently accessed data combinations, denormalized designs can significantly improve query speed. Although it does have the downside of paying for increased storage requirements and potential data inconsistencies.

Normalization in Machine Learning and Business Use Cases
Data normalization plays an important role in machine learning, business intelligence, and up-to-the-minute systems, going beyond just relational databases. As data pipelines grow more complex, proper normalization techniques become increasingly vital across various domains.
Data Normalization in Machine Learning Preprocessing
Data normalization is a key preprocessing step in machine learning that standardizes features. This standardization ensures equal contribution to model predictions. Models often do not perform well if individual features fail to follow a standard normal distribution with zero mean and unit variance.
Normalization can help models train faster by stopping gradient descent from bouncing and slowing convergence. Feature scaling techniques serve different purposes based on data distribution:
- Min-max scaling works best for uniformly distributed data with known bounds.
- Z-score normalization excels for normally distributed features.
- Log scaling helps when data follows a power law distribution such as movie ratings or book sales.
Features with wider ranges can overshadow those with narrower ranges without proper normalization. This causes models to miss important variables. It is worth mentioning that normalization prevents the NaN trap that happens when feature values exceed floating-point precision limits.
Normalization in Business Intelligence and Reporting Systems
Normalization builds strong foundations for analytics processes in business intelligence applications. The process organizes data consistently by removing redundancy and inconsistencies. This approach leads to better data storage, retrieval, and analysis. Business intelligence systems benefit from normalization through:
- Elimination of redundant data.
- Minimization of data duplication.
- Improved data consistency.
- Better data integrity.
Businesses can blend data from multiple sources for complete reporting and analysis since proper data normalization assists with interoperability.
Normalization vs Denormalization in Real-Time Systems
Real-time systems need a balance between consistency and performance when deciding between normalization and denormalization. Data normalization maintains integrity but might slow query responses due to join operations. Denormalization offers faster read performance but holds a higher risk of inconsistencies.
Denormalization becomes necessary for real-time data lakes and streaming applications where every millisecond counts, this is why many companies opt to use a hybrid approach in practice. They would normalize transaction-focused systems (OLTP) while denormalizing analytical systems (OLAP), where reporting speed matters more than updates. Discovering the right balance between normalized and denormalization structures helps companies maintain data quality and system responsiveness as they become more data-driven.
Conclusion
The article showed how data normalization changes chaotic, redundant information into well-structured, efficient databases. Data normalization forms the essence of proper database design and ensures data integrity and optimal performance.
The process follows logical steps that improve database quality. Moving through normal forms, from 1NF to BCNF, offers a systematic way to eliminate various data anomalies. It is an essential practice that directly affects how your systems work, rather than just a technical exercise. Properly normalized relational databases cut down data redundancy and prevent insertion, update, and deletion anomalies that are common in poorly designed systems. Normalization reaches beyond traditional databases as machine learning preprocessing depends on normalization techniques like Z-score scaling, min-max scaling, and log scaling.
Key Takeaways:
- Database normalization creates logical structures. Clear relationships mirror real-life entities when you organize data into distinct tables connected through primary and foreign keys.
- Each normal form addresses specific data integrity concerns. First Normal Form (1NF) eliminates repeating groups, Second Normal Form (2NF) removes partial dependencies, Third Normal Form (3NF) addresses transitive dependencies, and Boyce-Codd Normal Form handles complex candidate key situations.
- Normalization generally improves performance. Normalized databases typically reduce storage needs and improve performance for most operations, though they need more joins for complex queries.
- Real-life systems often balance normalization with denormalization. Selective denormalization might improve query performance where read operations dominate, especially in data lakes and analytical applications.
- Feature scaling normalization remains critical for machine learning. Models train effectively and produce reliable results when different data distributions are used with appropriate normalization techniques.
Learning and understanding normalization helps you design databases that last. The basic principles of reducing redundancy and maintaining integrity matter across database types, even through NoSQL databases that might handle data organization differently. These normalization concepts are the foundations for effective data management strategies, regardless of whether you work with traditional databases or modern big data architectures.





